

SOFA Session Ouverture
SOFA Session Ouverture
A case for those "heritage" architecture practices and a look at Zachman



There is a moment, perhaps many moments, in the journey through the technology world, a lifetime perhaps, where one might experience anxiety for lost practices. Those techniques and methods, hard learnt, now fading from view. In most cases this passing into history is well deserved. Good riddance, we say. Was this even a good idea? The past, as has been said, is a foreign country; they do things differently there.
Other ideas persist, however. They may fall out of use. They may become part of, what we might call, a background of practices. That is, they become pervasive and unarticulated (or perhaps un-articulable). Take, for example, non-functional (or quality) needs. 20 years ago (maybe more) there were formal methods. The Architectural Trade-off Method1 being an example. We learnt them, sometimes formally. They were incorporated into systems lifecycles. They were foremost in the disciplines of architecture. They were on CVs. The cloud, with its elastic scale, changed the conversation about NFRs. The methods atrophied, but they didn’t disappear. We still need to worry about particular qualities at certain points. But now it is a practice in the background.
In the world of IT architecture (of all types) we have sacred texts which sometimes persist; Eric Evan’s Domain Driven Design (the “Blue Book”) being a possible, and perhaps exceptional, example. But what about all those practices in the background? Those unremembered texts? I’m certainly not suggesting that we re-formalise these lost methods. Contemporary technology and systems engineering, for the most part, has surpassed their need. Maybe, however, it is possible to dust off some of the old ways to reenforce the practices we still use. Bring them a little forward, every now and then. It’s not the formality which has the benefit. It will be the way the concepts add to one’s overall knowledge; our bag of tools. In most respects it will be little tiny pieces of the old formalities which will have some relevance to the contemporary condition.
What does this mean?
I’d like to describe some architectural practices which I have found useful over the years. There is nothing new here. Rather, I want to describe some of those (nearly) forgotten approaches which may still have some relevance in the contemporary IT world. There will be nothing original. Rather just a re-articulation.
One other thing. Don’t do the work. There will no need to research or learn any of the practices in any detail to apply them. For one reason it would probably be hard to even find information on them. And they’re huge! Its about assessing whether the ideas fit and might extend our current a set of practices.
I want to start with one of the oldest architectural practices. Some of called it the DNA of organisational IT. That is, the Zachman Framework2.
A framework!? Yes, I know, who does frameworks any more? Especially architecture ones. There are corners of the IT world where we may come across them. But, hey, who wants to work there!
This one is even more meta than most. It’s a framework which attempts an ontology of IT. Which is, of course, crazy. In fact, that is enough to assign it to the past.
But! How might it help in understanding enterprise abstractions. Not abstraction in the CompSci sense, but abstraction in the architecture definition (or perhaps, description) sense. Ever wondered why some models (diagrams) looked a bit, well, odd? Why icons of API Gateways and database cylinders (ok, a pet hate) appeared on the same diagram as an icon of a truck representing goods being shipped from a warehouse? Ever considered what modelling approach to use for a specific problem, what ways there might be of working through a problem? Ever wondered why the programme or solution architect didn’t understand what you were describing? Zachman (the person, not the Framework) worried about this as well.
The Zachman Framework is very meta. It’s job was not to describe how to DO architecture (methods, notations, etc), rather it wanted to describe the structure of the architecture problem space at various layers of abstraction. This allowed the methods which followed in its footsteps to be compartmentalised (well, that was the idea, at least). A kind of periodic table for IT architecture. Of course, its meta-ness has probably enabled it to endure. OK, a random search on a random job site with 50 billion jobs (give or take) showed just 1 job with a Zachman reference. I’d call that a marginal practice.
The point of Zachman is to describe the “things” we do in delivering IT for the enterprise. All things! We’re not talking documents, or artefacts. The things we do could be ideas, conversations, whiteboard sessions. Typically we think “document” when we need to communicate widely (although it is disputable whether documents provide this quality) or compliance/governance people tell us we have to. Zachman goes as far as the software the runs on computers, whether that be software we’ve written ourselves, stuff we purchased, or services we rent. In the end, the final end-in-itself, of all those other layers, is this software which the business uses to do whatever the business does. That, for Zachman, is Enterprise Architecture. Everything from the thinking, planning, modelling, engineering, and operating IT.
Let’s first look at its structure. If you search for Zachman (you probably won’t) you’ll probably find ONE image. All that is left of the framework is just one image!

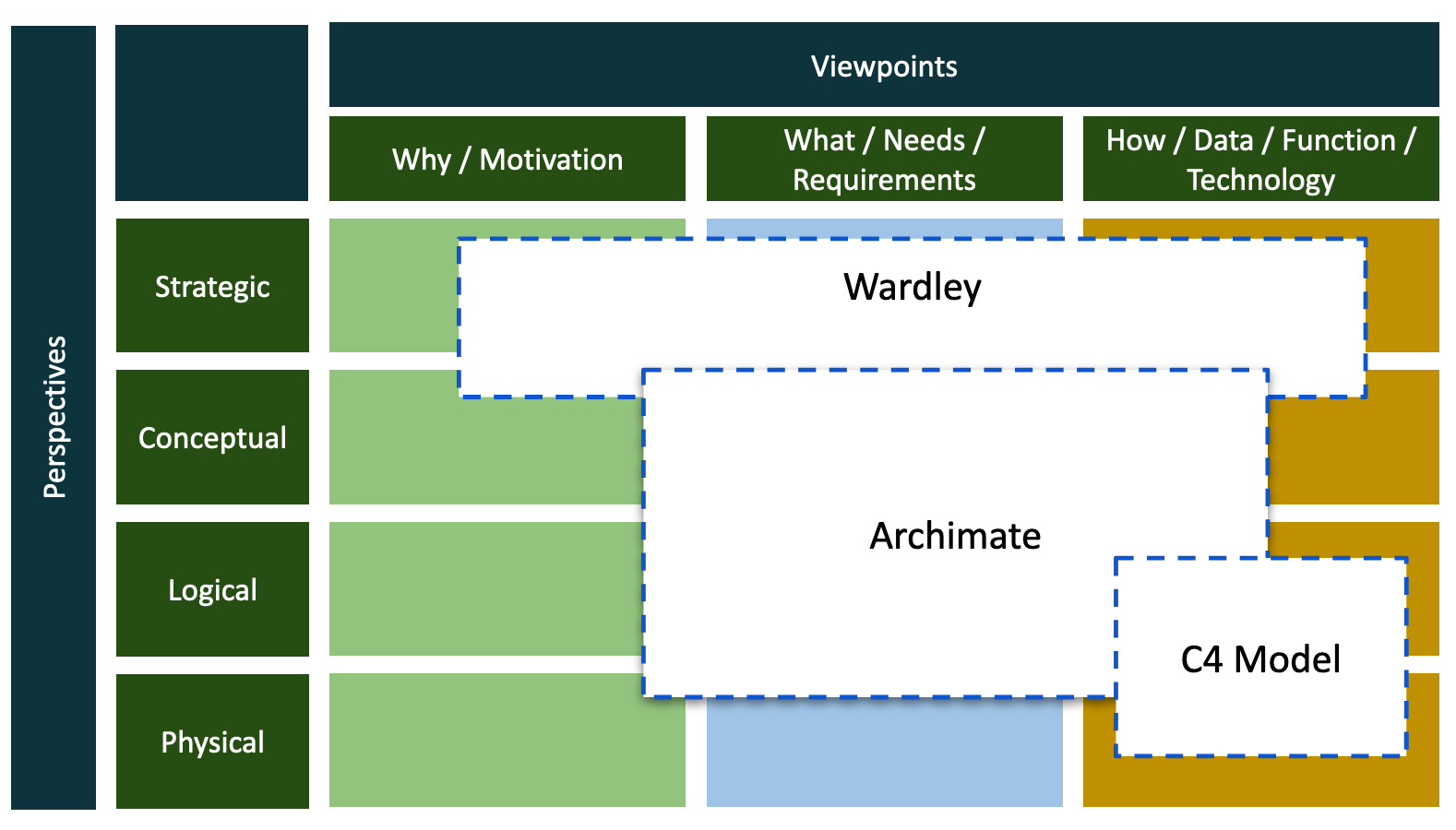
This is, of course, a brutal summarisation. But, then again, its unlikely you’ll check up on me. In all its meta-ness; 12 cells. Actually, the original has 30 cells, but who has time for that? The Framework is essentially a 2-dimensional table, I’m going to call them perspectives and views. Although I frequently invert these; those viewpoints should be perspectives….no wait…. And so on.
The columns are views (or viewpoints). These are the practices we might use to look at a problem space (for Zachman, the problem space is the entire IT world within an organisation—from a startup to a multi-national or government agency). The columns are the fundamental types of questions we ask about problem space. We can call these the “why”, “what” and “how” of IT. The why is the rationale for dealing with the problem. The what is what are we going to do about it? The how is how are we going to tackle it. Motivation, requirements, and technology. Simple enough.
The rows (or layers) I’m calling perspectives. Perspectives are the layers of abstraction within the problem space. They are the types (roles) of people who look at the problem space; the types of architecture we might use to describe the space. Again summarising brutally, the top-most abstraction is strategic, the IT planning and strategy elements. Next we have the conceptual perspective, architecting the strategy, which is enterprise-wide. Logical is the layer which starts to think in systems, or systems of systems. Programmes of work. Physical represents actual systems which are engineered (sometimes developed) and deployed. Zachman also uses roles to name these columns; Planner, Owner, Designer, and Builder respectively (there is also a sub-contractor layer).
The magic, if there is any, is the intersection of viewpoints and perspectives. The cells. Each cell gives us hint into the types of architecture we’ll be doing (and the type of architect we might need), and the level at which we’ll be doing it. It also tells us the inputs we might expect to receive (layer “N-1”) and the outputs we might expect to produce (layer “N+1”).
So, for instance, at the strategic perspective we’ll be focusing on turning business strategy into IT strategy. At the logical perspective we’ll for focusing on turning business/IT programmes architecture into solution architectures. At the physical perspective we might be turning solution building blocks into systems.
Take a single cell. A specific perspective and viewpoint. Remembering that Zachman is a framework rather than a method (in fact, as a framework, it provides a framework for method development). Conveniently, this means that Zackman is not going to tell us what to do; a reasonably quality of a framework, I reckon. We can use the “position” of the cell to aid us in determining the architectural approaches to use. I’m using the term “approach” as a catchall for the architecture “things we do to understand the problem and define possible solutions”. The methods, descriptive techniques, practices, knowledge, tools, processes, etc, that help us “do architecture”. We’re also able to determine the type of skills we might need, and potentially the type of research we might need to do.
Simple as that. It almost seems banal.
The cells are related to each other. At the same layer each cell informs the other, creating a wide picture of the problem space. Between layers we have a flow down of abstractions, with these abstractions becoming increasing concrete. To the point where some software is running on some hardware.
It’s worthwhile to note that, with Zachman, the assumption is that layers flow downwards. As we will see, the contemporary architecture world does not work like this.
At layer “N” the definition of Why and What (which are opaque to the How) are realised by the How. Realised to a certain level of abstraction, defined by its perspective. The Why, What, and How of layer “N-1” provides the coarse abstractions for layer “N”. To dig a little into this, the realisation (the How) forms part of the requirements for the layer below (we’ll see how this works in a future article).
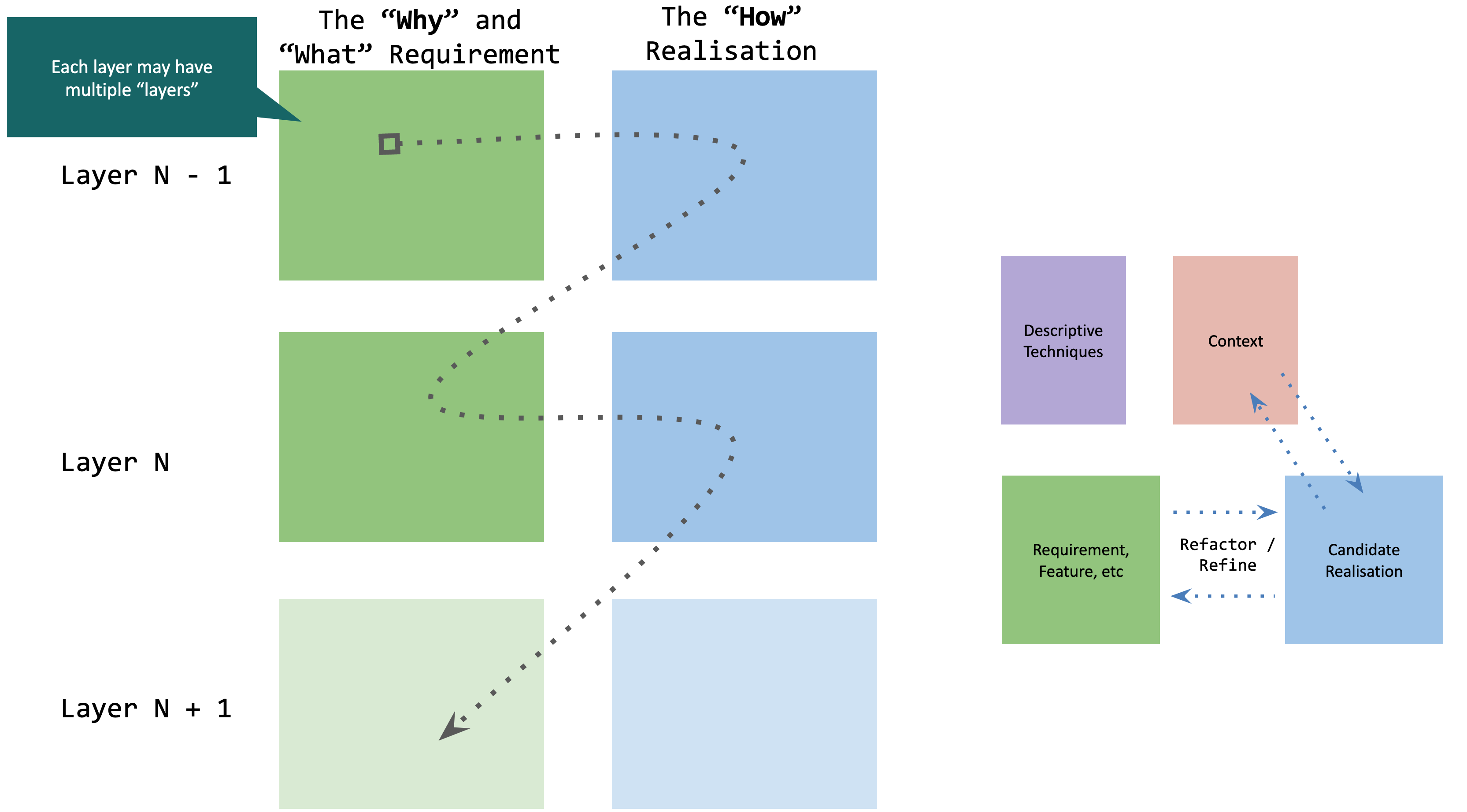
Say, for example, you are working on the application architecture of a microservice (layer “N”). How did the architectural boundary of the service get defined? At layer “N-1”, in the systems architecture probably. How did we even decide to do microservices? Because the enterprise-wide (conceptual layer) strategy said we should. Why did we choose microservices for the organisation? Because the IT strategy was responding to a digital transformation and the CTO wanted to be like Netflix (other rationale are available).
Of course, it all looks very ordered. It isn’t. Firstly, while the cells implies a separation of practices into clean boundaries, this is never the case in practice. Its messy in there. Very messy. Lots of things are happening at once and chaotically. Along with flow down (IT executives love flow down), we have flow-up, flow-from-the-centre-outwards, random flow-seagulls-doing-seagull-things-to-the-flow, and so on. The politics of people and organisational interactions are nowhere on the map. But Zachman doesn’t have to care about this; its a framework, after all.
One “rational” change to the historical Zachman view we might apply is the “shift-left” concept. Agile practices have moved a bunch of decision making that, in the framework, were designed to be made in upper layers down to the people-doing-the-work. That doesn’t change the framework, if just means that the people-doing-the-work are operating at multiple levels of perspective.
How might we use this ancient of all frameworks?
Let’s say we’re working in a programme to deliver some cross domain solution; it can be anything you can imagine. Let’s also say we working in the data world, that is, our role is to do data things. Not that we don’t also worry about motivations, requirements, and technologies, but we’re primarily focused on data and data analytics.
What questions can we use Zachman to help us to answer?
Well, firstly, we may want to understand what layer we’re working at when we doing our work (remember, you never operate at 1 single layer exclusively). We already know, because of our data bias, that we mostly in the How column with input into and interest in the What. But what layer? We’ll, let’s say we‘re NOT designing data models for individual systems, but we are working on the data architecture for a programme of work. This puts us in the Logical viewpoint. Of course we move up and down in the same fashion we move left and right.
The modelling techniques applicable for this cell. Its about data and is wider than an application’s data model but narrower than the enterprise data models (who does that these days?). Perhaps a DDD3 context map might fit. We might use logical data models or consider data product models. Hell, we might go all in on a semantic model of the domain.
Model abstraction; that is, what gets included on the model? At this level of abstraction we might want to include the most significant nouns in the problem space, but we won’t care to much about attributes/properties.
Evolving the data strategy. Strategy (upper layers/perspectives) may dictate principles and strategic approaches for data managing (e.g. we’re doing Data Mesh, Digital transformation with a digital customer at the centre, etc). This layer takes these strategic statements are makes it more “real”.
Up a layer, down a layer. The previous point suggests a relation to cells and layers in immediate proximity to the layer we’re working in. We get our “requirements” (actually, more abstract definitions) from the layer (and cell) above, and we provide “requirements” to the cell below. Models at layer “N” communicate how we intend to fulfil the needs defined at layer “N-1”. Layer “N-1” are stakeholders for our work, our architecture. While layer layer “N+1” are recipients of our needs. In reality, of course, crossing layers is far more messy and iterative. Remember that shift-left theme?
What type of architect role are we performing? The layer in which we are working suggests the skills required. We might typically work at an application architecture layer. Working at a systems architecture perspective requires that we raise our level of abstraction level; change the level we care about. Adopt different practices.
The cells provide structural patterns for understanding specific methodological or descriptive techniques. These are layer dependent. For example, we may use Wardley Maps at the strategic layers and C4 models at the system layers. We might even decide, if we have the patience to get through the hundreds of pages of documentation, to use Archimate which can be stretched across multiple viewpoints and perspectives.
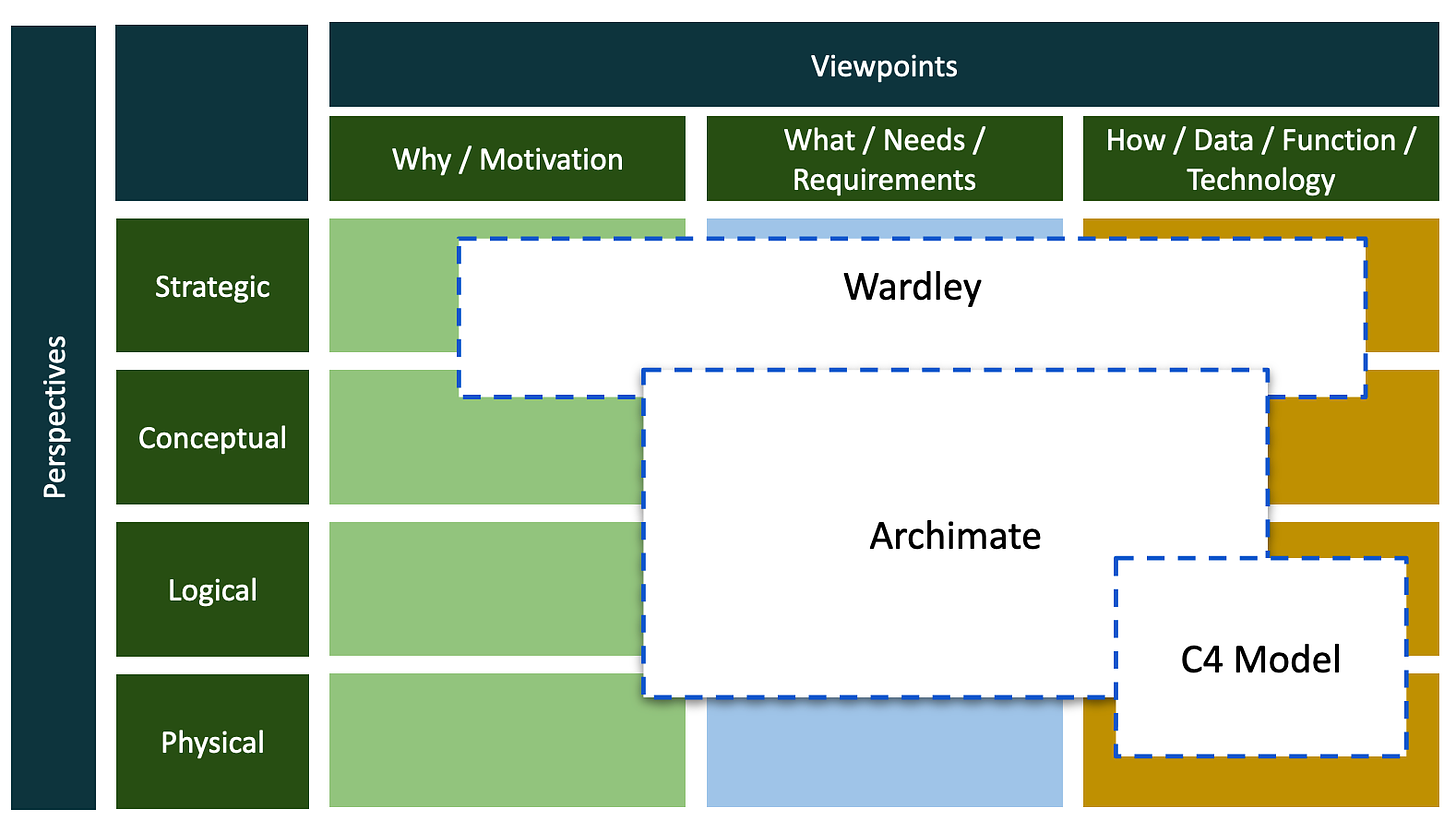
The big methods. Extending the point above, we may have to deal with uber-methods (I’m using “method” very loosely here, as we might be faced with frameworks, practices, etc) for “doing architecture”. Understanding how such a method is positioned it within the cell pattern can help in determining it’s fitness for purpose. There is no ONE method to rule them all. No method developer will ever suggest there is. However, methods can blur across the views and perspectives. Therefore its about making choices as to what approach to use. For example, at the strategic perspectives, Enterprise Architecture practitioners might apply the TOGAF4 method/framework, or SAFe’s5 lean portfolio management practices. Where as we might use DDD’s strategic patterns and Semantic Modelling techniques at the systems perspective.
Just knowing the layer we’re working in helps guide our architecture practice. Understanding the layer(s)/cell(s) being discussed at the whiteboard (other media is possible) helps centre the conversation, keeping it on track, and ensuring our sketches are at the correct layer of abstraction.
It’s easy to discount these ancient works, and in some (most?) cases for very good reason. But, as someone once said, knowing history means that we are not doomed to repeat it. Or something like that. We are probably in an anti-method era. It is difficult to even identify methods we use today (I’m ignoring vendor methods designed specifically for lock-in). In contemporary engineering, the team decides. And, perhaps, for good reason. However, just sometimes, there are some old techniques that can help us in this (post-) modern world in which we work.
And remember, if in doubt, stay safe and avoid frameworks.
https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=5177
The Zachman Framework was created by John Zachman, in the 1980s.
Domain Driven Design.
The Open Group’s Architecture Framework.
The Scaled Agile Framework.
 | A guest post by
|